![]()
INFORMATICA - PROGRAMMAZIONE: I FILE
I FILE
Nella programmazione interessa la gestione dei file di dati. Essi permettono di memorizzare dei dati, con una opportuna organizzazione, su una memoria di massa (nastro o disco). Il file può essere pensato come una successione di record; non esiste un limite al numero di record che possono essere contenuti nel file, se non dovuto alla capacità del supporto su cui il file è registrato. Durante l'elaborazione si può accedere soltanto a un record per volta; i dati del record a cui si accede vengono resi disponibili tramite un'area di memoria riservata al file detta area record. Tramite quest'ultima vengono eseguite le operazioni di input/output logiche.![]()
![]()
I METODI DI ORGANIZZAZIONE E DI ACCESSO
Per definire un file è necessario stabilire il metodo di organizzazione, cioè il metodo con cui le informazioni sono registrate sul supporto. Per i file su nastro esiste un unico tipo di organizzazione possibile, quella sequenziale. Per i file su disco esistono organizzazioni diverse:- sequenziale
- indexed (sequenziale con indice)
- diretta
- relative (relativa)
Secondo il tipo di organizzazione è possibile accedere ai record in modo diverso. Per utilizzare un file in un programma bisogna specificare sia il tipo di organizzazione che il metodo di accesso usati. Comunque, se il tipo di accesso può variare da un programma all'altro per uno stesso file, secondo il tipo di elaborazione necessario, il tipo di organizzazione invece fa parte della definizione stessa del file. Il file deve quindi essere considerato organizzato sempre secondo il metodo con cui è stato creato, dato che per organizzazioni diverse i dati vengono registrati fisicamente in modo differente. Nell'algoritmo e nel programma non è necessario preoccuparsi di come i dati siano fisicamente registrati sul supporto; basta conoscere il metodo di organizzazione e decidere come accedere ai dati mediante le istruzioni rese disponibili dal linguaggio di programmazione usato; sono poi le routine del sistema operativo che si occupano di tradurre queste istruzioni nelle operazioni necessarie all'effettiva gestione dei dati sul supporto magnetico.
![]()
![]()
I FILE AD ORGANIZZAZIONE SEQUENZIALE
L'APERTURA E LA CHIUSURA DEL FILE
Ogni file, per poter essere utilizzato, deve essere aperto, cioè reso disponibile al programma, mediante un'apposita istruzione. Con questa si rende disponibile al programma l'area record associata al file (senza dati). Al momento dell'apertura, deve essere indicato in che modo il file deve essere reso disponibile:INPUT: solamente per la lettura
OUTPUT: solamente per la scrittura
INPUT/OUTPUT: sia per lettura che per scrittura
EXTEND (o APPEND): solamente per la scrittura.
La differenza tra apertura in OUTPUT e in EXTEND consiste nel fatto che in OUTPUT si predispone il file a ricevere dati come se fosse vuoto. Se il file conteneva già dei record, questi vengono perduti al momento di una apertura in OUTPUT e si ricomincia l'inserimento dall'inizio del file.
L'apertura in EXTEND invece predispone il file a ricevere dati in aggiunta a quelli già contenuti; il file cioè si estende a contenere altri record, dopo quelli già inseriti. Le operazioni ammesse per ogni file usato nel programma dipendono dal tipo di apertura richiesto. Quando il file non viene più utilizzato deve essere chiuso mediante un'istruzione che provvede a rilasciare correttamente il file.
LA CREAZIONE DI UN FILE SEQUENZIALE
Per un file ad organizzazione sequenziale si può pensare che i record siano registrati uno dopo l'altro nell'ordine in cui vengono inseriti. La registrazione di record è consentita se il file è aperto in output o in extend. Ogni operazione di scrittura inserisce un record nel file in successione. I record sono contenuti nel file nell'ordine in cui sono stati inseriti. Nel record devono essere stati predisposti i dati che devono essere scritti nel file.Uno schema generale per la creazione di un file sequenziale, introducendo i dati da tastiera, è il seguente: inizio apertura del file in output richiesta di continuazione lettura RISPOSTA mentre RISPOSTA = "S" richiesta dati lettura dati preparazione dati del record inserimento record richiesta di continuazione lettura RISPOSTA fine mentre chiusura del file fine Ai record memorizzati è possibile fare riferimento soltanto nello stesso ordine con cui sono stati registrati; per esaminare l'ultimo record, per esempio, è necessario scorrere tutti quelli che lo precedono.
Tale tipo di accesso si dice sequenziale ed è l'unico consentito per i file con tale organizzazione. Eventuali inserimenti di nuovi record possono essere effettuati soltanto in coda al file. Variazioni di record già immessi sono consentite soltanto per i file registrati su disco (non per quelli registrati su nastro). La lettura del file rende disponibile un record per volta. Il file deve essere aperto in input o in input-output.
Ad ogni nuova lettura i dati del record precedente vengono persi (se sono necessari per operazioni successive devono essere opportunamente memorizzati all'interno del programma). Un tentativo di leggere oltre l'ultimo record registrato causa l'attivazione di un segnale che indica la fine del file.
La fine del file (End of File - EOF) viene segnalata in modi diversi secondo le implementazioni: in alcuni casi è possibile riconoscere immediatamente mediante un test che il file è vuoto o che ne è stata raggiunta la fine; in altri, la fine del file viene riconosciuta soltanto ad una lettura successiva a quella dell'ultimo record registrato. In ogni caso bisogna fare attenzione perché il programma non tenti di elaborare anche record inesistenti. Uno schema generale per la lettura di un file sequenziale, se la fine del file può essere riconosciuta direttamente (per esempio utilizzando una funzione) è il seguente: inizio apertura del file in input mentre non è la fine del file lettura del file {viene letto un record} elaborazione del record fine mentre chiusura del file fine ESEMPIO 41 Questo programma permette di creare un file sequenziale contenente i dati degli articoli venduti da una ditta. Tracciato del file PRODOTTI:
+----------------------------------------------------------------+ ¦cod. prodotto ¦ descrizione ¦ prezzo ¦ scorta minima ¦ giacenza ¦ +----------------------------------------------------------------+COD.PRODOTTO: codice identificativo dell'articolo;
DESCRIZIONE: descrizione dell'articolo;
PREZZO: prezzo di vendita;
SCORTA MINIMA: la quantità minima di articoli che deve essere presente in magazzino per poter soddisfare le normali richieste di acquisto;
GIACENZA: la quantità di articoli realmente presente in magazzino.
Descrizione delle variabili:
+----------------------------------------------------------------+ ¦ NOME ¦ TIPO ¦ I/O ¦ SIGNIFICATO ¦ +-----------+-------------+------------------+-------------------¦ ¦ TIPO- ¦numero intero¦ input ¦ segnale che può ¦ ¦ APERTURA ¦ ¦ ¦ assumere i valori:¦ ¦ ¦ ¦ ¦ 0 = creazione del ¦ ¦ ¦ ¦ ¦ file; 1 = aggiunta¦ ¦ ¦ ¦ ¦ dati in coda al ¦ ¦ ¦ ¦ ¦ file ¦ ¦ RISPOSTA ¦alfanumerico ¦ input ¦ segnale che indica¦ ¦ ¦ ¦ ¦ se continuare ¦ ¦ ¦ ¦ ¦ l'elaborazione o ¦ ¦ ¦ ¦ ¦ terminare ¦ +----------------------------------------------------------------+Flow chart Esempio 41 (prima parte)
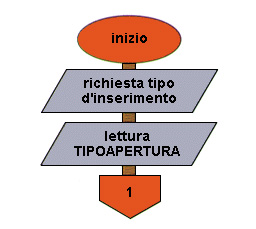
Flow chart Esempio 41 (seconda parte)
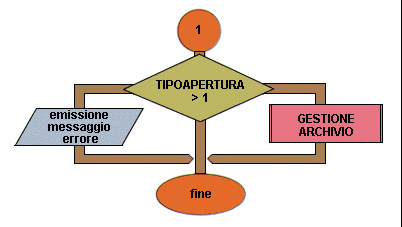
Flow chart Esempio 41 (terza parte)
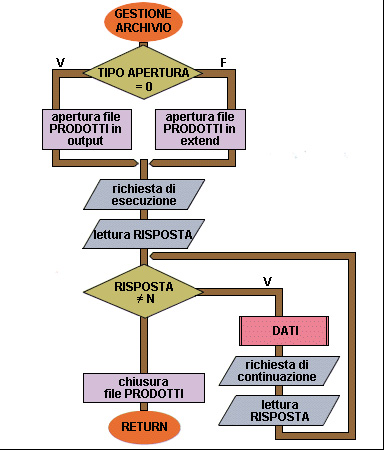
Flow chart Esempio 41 (quarta parte)

Pseudocodifica (vedi Figure)
1 inizio
2 emissione richiesta tipo di lavoro
3 lettura TIPOAPERTURA
4 se TIPOAPERTURA > 1 allora
5 emissione messaggio di errore
6 altrimenti
7 GESTIONEARCHIVIO
8 fine se
9 fine
10 inizio GESTIONEARCHIVIO
11 se TIPOAPERTURA = 0 allora
12 apertura file PRODOTTI in output
13 altrimenti
14 apertura file PRODOTTI in extend
15 fine se
16 emissione richiesta di continuazione
17 lettura RISPOSTA
18 mentre RISPOSTA > "N" esegui
19 DATI
20 emissione richiesta di continuazione
21 lettura RISPOSTA
22 fine mentre
23 chiusura file PRODOTTI
24 fine GESTIONEARCHIVIO
25 inizio DATI
26 emissione richiesta dati prodotto
27 lettura CODICE
28 lettura DESCRIZIONE
29 lettura PREZZO
30 lettura SCORTAMINIMA
31 lettura GIACENZA
32 inserimento record nel file PRODOTTI
33 fine DATI da 1 a 9
Programma principale.
2-3 Viene richiesto all'utente se aggiungere i dati in fondo a un file esistente o se considerare il file come nuovo.
Da 4 a 8 controllo del valore inserito: sono ammessi solo i valori 0 e 1; il procedimento continua solo se il valore inserito è corretto.
Da 10 a 22 procedura per la gestione del file.
12 Aprendo il file in output eventuali dati già presenti vengono cancellati; se il file non esiste viene creato.
14 Con l'apertura in extend i dati inseriti vengono aggiunti in coda a quelli già presenti.
Da 18 a 24 ciclo per l'inserimento dei dati dei nuovi articoli; il ciclo termina in base ad una risposta dell'utente.
Da 25 a 33 procedura per l'inserimento dei dati di un articolo.
Da 26 a 31 richiesta dei dati all'utente.
32 Scrittura dei dati nel file.
ESEMPIO 42.
Una ditta vuole determinare, tra i prodotti conservati in magazzino, per quali prodotti si ha la scorta di maggiore e minor valore, calcolando il valore della merce come quantità in magazzino moltiplicato per il prezzo di vendita; vuole inoltre determinare qual è il valore medio delle scorte dei diversi articoli. I dati relativi ai prodotti sono registrati in un file PRODOTTI sequenziale con tracciato:
+----------------------------------------------------------------+ ¦cod. prodotto ¦ descrizione ¦ prezzo ¦ scorta minima ¦ giacenza ¦ +----------------------------------------------------------------+
Descrizione delle variabili:
+----------------------------------------------------------------+ ¦ NOME ¦ TIPO ¦ I/O ¦ SIGNIFICATO ¦ +-----------+-------------+------------------+-------------------¦ ¦ CODICE- ¦ numerico ¦ output ¦ codice dell'arti- ¦ ¦ MASSIMO ¦ ¦ ¦ colo di valore ¦ ¦ ¦ ¦ ¦ massimo ¦ ¦DESCRIZIONE¦ alfanumerico¦ output ¦ descrizione ¦ ¦ MASSIMO ¦ ¦ ¦ dell'articolo di ¦ ¦ ¦ ¦ ¦ valore massimo ¦ ¦ MASSIMO ¦ numerico ¦ output ¦ valore massimo ¦ ¦ CODICE- ¦ numerico ¦ output ¦ codice dell'arti- ¦ ¦ MINIMO ¦ ¦ ¦ colo di valore ¦ ¦ ¦ ¦ ¦ minimo ¦ ¦DESCRIZIONE¦ alfanumerico¦ output ¦ descrizione ¦ ¦ MINIMO ¦ ¦ ¦ dell'articolo di ¦ ¦ ¦ ¦ ¦ valore minimo ¦ ¦ MINIMO ¦ numerico ¦ output ¦ valore minimo ¦ ¦ MEDIO ¦ numerico ¦ output ¦ valore medio dei ¦ ¦ ¦ ¦ ¦ prodotti in ¦ ¦ ¦ ¦ ¦ magazzino ¦ ¦ VALORE ¦ numerico ¦ interno ¦ valorizzazione ¦ ¦ ¦ ¦ ¦ di un prodotto ¦ ¦ ¦ ¦ ¦ del magazzino ¦ ¦ VALORE- ¦ numerico ¦ interno ¦ somma dei valori ¦ ¦ TOTALE ¦ ¦ ¦ dei prodotti in ¦ ¦ ¦ ¦ ¦ magazzino ¦ ¦ TIPI- ¦ numerico ¦ interno ¦ numero dei tipi di¦ ¦ PRODOTTO ¦ ¦ ¦ prodotti presenti ¦ +----------------------------------------------------------------+Flow chart Esempio 42 (prima parte)
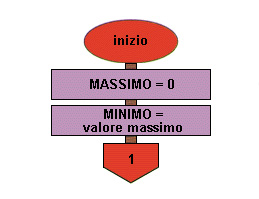
Flow chart Esempio 42 (seconda parte)
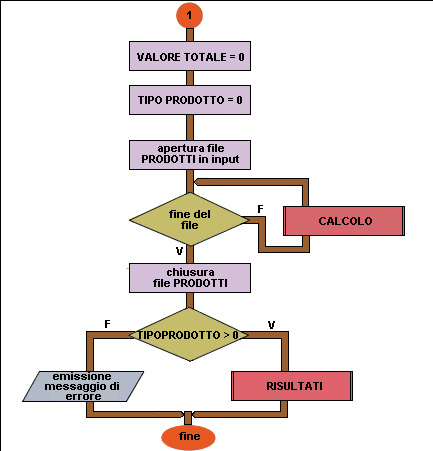
Flow chart Esempio 42 (terza parte)
Flow chart Esempio 42 (quarta parte)
Pseudocodifica (vedi Figure)
1 inizio
2 MASSIMO = 0
3 MINIMO = limite massimo
4 VALORETOTALE = 0
5 TIPIPRODOTTO = 0
6 apertura file PRODOTTI in input
7 mentre non è finito il file esegui
8 CALCOLO
9 fine mentre
10 chiusura file PRODOTTI
11 se TIPIPRODOTTO > 0 allora
12 RISULTATI
13 altrimenti
14 emissione messaggio di errore
15 fine se
16 fine
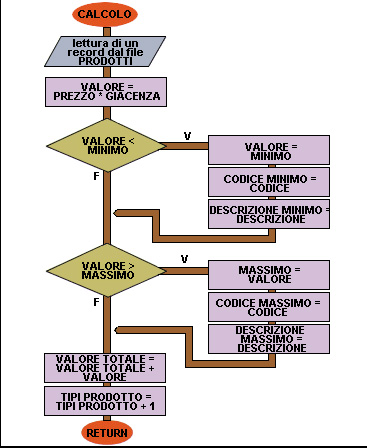
17 inizio CALCOLO
18 lettura di un record dal file PRODOTTI
19 VALORE = PREZZO x GIACENZA
20 se VALORE MINIMO allora
21 MINIMO = VALORE
22 CODICEMINIMO = CODICE
23 DESCRIZIONEMINIMO = DESCRIZIONE
24 fine se
25 se VALORE > MASSIMO allora
26 MASSIMO = VALORE
27 CODICEMASSIMO = CODICE
28 DESCRIZIONEMASSIMO = DESCRIZIONE
29 fine se
30 VALORETOTALE = VALORETOTALE + VALORE
31 TIPIPRODOTTO = TIPIPRODOTTO + 1
32 fine CALCOLO
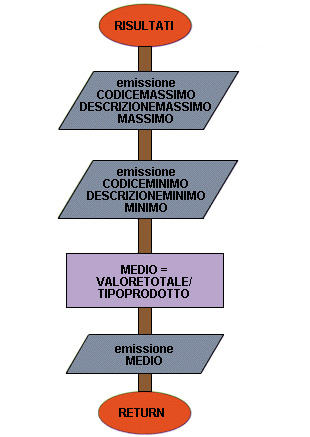
33 inizio RISULTATI
34 emissione CODICEMASSIMO DESCRIZIONEMASSIMO MASSIMO
35 emissione CODICEMINIMO DESCRIZIONEMINIMO MINIMO
36 MEDIO = VALORETOTALE / TIPIPRODOTTO
37 emissione MEDIO
38 fine RISULTATI
Da 1 a 16 programma principale.
Da 2 a 5 inizializzazione delle variabili per il calcolo dei valori minimo e massimo e della media dei valori.
6 Apertura del file in input: i dati devono essere soltanto letti.
Da 7 a 9 ciclo di elaborazione del file; il ciclo termina quando il file è finito.
10 Chiusura del file.
12 Se il file conteneva dei record vengono stampati i risultati desiderati.
14 Se il file è vuoto viene segnalato un errore.
Da 17 a 32 procedura per l'elaborazione dei dati di un articolo.
18 Lettura di un record; i dati del record vengono resi disponibili per l'elaborazione.
19 Calcolo del valore di un articolo.
Da 20 a 24 confronto col valore minimo determinato in precedenza. Se il valore calcolato è più piccolo vengono memorizzati il codice, la descrizione e il valore dell'articolo.
Da 25 a 29 confronto col valore massimo determinato in precedenza. Se il valore calcolato è più piccolo vengono memorizzati il codice, la descrizione e il valore dell'articolo.
30 Calcolo del valore totale degli articoli per la determinazione del valore medio.
31 Calcolo del numero di tipi di articoli presenti per la determinazione del valore medio.
Da 33 a 38 procedura per la stampa dei risultati.
34-35 Stampa del codice, della descrizione e del valore degli articoli di valore massimo e minimo.
36-37 Calcolo e stampa del valore medio degli articoli del magazzino.
![]()
Guadagnare navigando! Acquisti prodotti e servizi.
Guadagnare acquistando online.
![]()
L'AGGIORNAMENTO DI FILE SEQUENZIALI
In un file sequenziale non è possibile inserire nuovi record tra gli altri già esistenti; per risolvere il problema è necessario ricopiare il file eseguendo le modifiche volute. Nei problemi di aggiornamento di file sequenziali in genere le modifiche da apportare al file originale vengono preparate in un secondo file; elaborando il file originale e il file delle variazioni si può ottenere il nuovo file contenente tutti i dati aggiornati.ESEMPIO 43.
Dato il file sequenziale PRODOTTI contenente le informazioni riguardanti gli articoli gestiti da una ditta, si vogliono apportare alcune variazioni ai dati registrati ed inserire dati relativi a nuovi articoli; i nuovi dati sono registrati in un secondo file sequenziale con lo stesso tracciato. I record del file VARIAZIONI il cui codice è presente anche nel file originale rappresentano variazioni da apportare, mentre i record il cui codice è presente soltanto nel file VARIAZIONI rappresentano nuovi inserimenti. In entrambi i file i record sono registrati in ordine crescente di codice prodotto; dopo le variazioni e gli inserimenti si vuole ottenere un file ancora ordinato per codice prodotto. Tracciato record dei file ORIGINE, contenente i dati sugli articoli, VARIAZIONI contenente le variazioni da apportare al file articoli e NUOVO, che conterrà i dati aggiornati:
+----------------------------------------------------------------+ ¦ cod.prodotto ¦ descrizione ¦ prezzo ¦ scorta minima ¦ giacenza ¦ +----------------------------------------------------------------+
CODICEORIGINE nome del campo codice prodotto nel file ORIGINE; CODICEVARIAZIONI nome del campo codice prodotto nel file VARIAZIONI. L'elaborazione consiste nelle operazioni di:
- lettura di un record dai file (o da uno solo, secondo i casi), fino alla fine di entrambi i file; bisogna quindi prevedere la gestione del caso di fine di uno solo dei due file;
- confronto dei codici articolo letti da ciascun file e trascrizione di uno dei due record nel nuovo file, secondo l'esito del confronto. Descrizione delle variabili:
+----------------------------------------------------------------+ ¦ NOME ¦ TIPO ¦ I/O ¦ SIGNIFICATO ¦ +-----------+-------------+------------------+-------------------¦ ¦ LETTURA- ¦ booleano ¦ interno ¦ segnale che può ¦ ¦ ORIGINE ¦ ¦ ¦ assumere i valori ¦ ¦ ¦ ¦ ¦ "vero" = bisogna ¦ ¦ ¦ ¦ ¦ eseguire una ¦ ¦ ¦ ¦ ¦ lettura del file ¦ ¦ ¦ ¦ ¦ ORIGINE, "falso" =¦ ¦ ¦ ¦ ¦ non si deve ¦ ¦ ¦ ¦ ¦ eseguire una ¦ ¦ ¦ ¦ ¦ lettura del file ¦ ¦ ¦ ¦ ¦ ORIGINE ¦ ¦ LETTURA- ¦ booleano ¦ interno ¦ segnale che può ¦ ¦ VARIAZIONI¦ ¦ ¦ assumere i valori:¦ ¦ ¦ ¦ ¦ "vero" = bisogna ¦ ¦ ¦ ¦ ¦ eseguire una ¦ ¦ ¦ ¦ ¦ lettura del file ¦ ¦ ¦ ¦ ¦ VARIAZIONI, "falso¦ ¦ ¦ ¦ ¦ = non si deve ¦ ¦ ¦ ¦ ¦ eseguire una ¦ ¦ ¦ ¦ ¦ lettura del file ¦ ¦ ¦ ¦ ¦ VARIAZIONI ¦ +----------------------------------------------------------------+Flow chart Esempio 43 (prima parte)
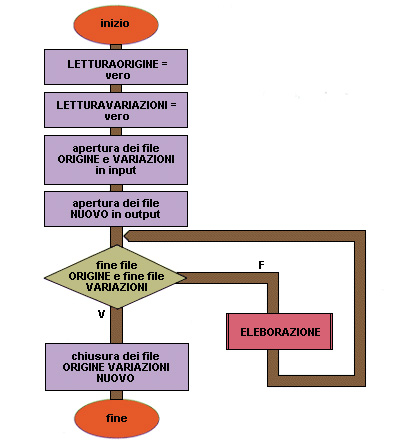
Flow chart Esempio 43 (seconda parte)
Flow chart Esempio 43 (terza parte)
Flow chart Esempio 43 (quarta parte)
Flow chart Esempio 43 (quinta parte)
Flow chart Esempio 43 (sesta parte)
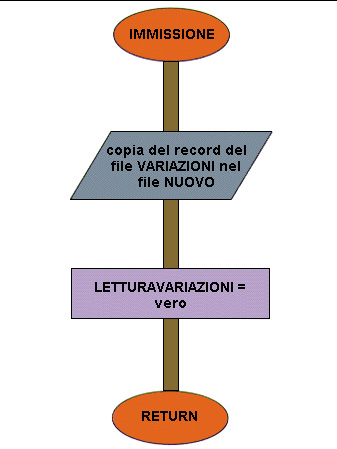
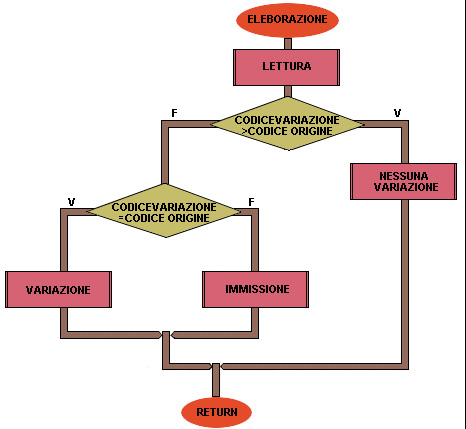
Pseudocodifica (vedi Figure)
1 inizio
2 LETTURAORIGINE = vero
3 LETTURAVARIAZIONI = vero
4 apertura dei file ORIGINE VARIAZIONI in input
5 apertura del file NUOVO in output
6 mentre non è finito il file ORIGINE o non è finito il file VARIAZIONI allora
7 ELABORAZIONE
8 fine mentre
9 chiusura dei file ORIGINE VARIAZIONI e NUOVO
10 fine
11 inizio ELABORAZIONE
12 LETTURA
13 se CODICEVARIAZIONE > CODICEORIGINE allora
14 NESSUNAVARIAZIONE
15 altrimenti
16 se CODICEVARIAZIONE = CODICEORIGINE allora
17 VARIAZIONE
18 altrimenti
19 IMMISSIONE
20 fine se
21 fine se
22 fine ELABORAZIONE
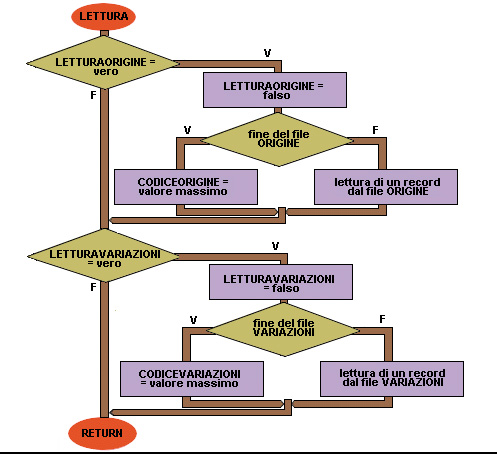
23 inizio LETTURA
24 se LETTURAORIGINE = vero allora
25 LETTURAORIGINE = falso
26 se il file è finito allora
27 CODICEORIGINE = valore massimo
28 altrimenti
29 lettura di un record dal file ORIGINE
30 fine se
31 fine se
32 se LETTURAVARIAZIONI = vero allora
33 LETTURAVARIAZIONI = falso
34 se il file è finito allora
35 CODICEVARIAZIONE = valore massimo
36 altrimenti
37 lettura di un record dal file VARIAZIONI
38 fine se
39 fine se
40 fine LETTURA
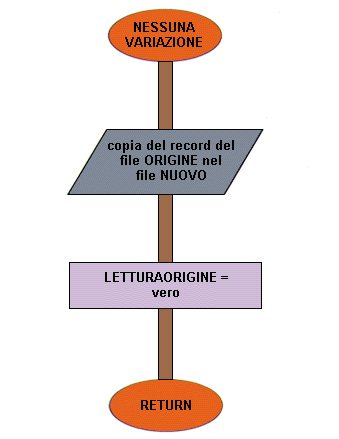
41 inizio NESSUNAVARIAZIONE
42 scrittura del record del file ORIGINE nel file NUOVO
43 LETTURAORIGINE = vero
44 fine NESSUNAVARIAZIONE
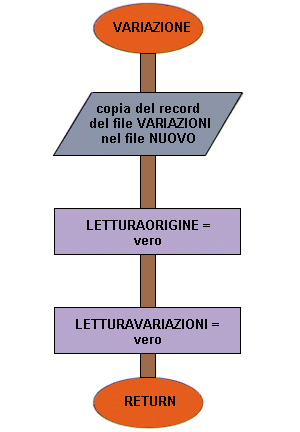
45 inizio VARIAZIONE
46 scrittura del record del file VARIAZIONI nel file NUOVO
47 LETTURAORIGINE = vero
48 LETTURAVARIAZIONI = vero
49 fine VARIAZIONE
50 inizio IMMISSIONE
51 scrittura del record del file VARIAZIONI nel file NUOVO
52 LETTURAVARIAZIONI = vero
53 fine
IMMISSIONE da 1 a 10 programma principale.
2-3 Il programma deve iniziare leggendo un record dal file origine e un record dal file variazioni; nella routine di lettura l'operazione di lettura di ciascun file di input dipende dallo stato di un segnale, poiché la stessa routine verrà usata anche nel resto dell'elaborazione; all'inizio entrambi i segnali sono posti a "vero" per poter effettuare la lettura di un record da ciascun file.
4-5 Apertura dei file. I file ORIGINE e VARIAZIONI vengono aperti in input; il file NUOVO deve essere creato e viene quindi aperto in output.
Da 6 a 8 ciclo di elaborazione per la creazione del file aggiornato; il ciclo termina quando sono stati letti ed elaborati tutti i record sia del file ORIGINE che del file VARIAZIONI. Se uno solo dei file è finito il procedimento continua.
9 Chiusura dei file.
Da 11 a 22 procedura di elaborazione per l'aggiornamento del file.
12 Viene richiamata la procedura lettura che provvede a leggere i record necessari dai file ORIGINE e VARIAZIONI; la prima volta viene letto un record dal file ORIGINE e un record dal file VARIAZIONI.
Da 13 a 21 L'elaborazione consiste nel confrontare i codici dei record letti dal file origine e dal file variazioni; poiché i record nei file sono in ordine di codice si possono verificare le seguenti situazioni:
13 codice record variazioni > codice record origine:
il codice del record origine è presente solo nel file origine e non nel file variazioni;
i dati non devono quindi essere variati, inoltre non ci sono articoli da inserire prima di questo, perché avrebbero codice minore;
viene quindi richiamata la procedura NESSUNA VARIAZIONE che provvede a riportare il record letto nel file NUOVO e a impostare a "vero" la variabile LETTURAORIGINE perché per l'elaborazione successiva si deve leggere un altro record dal file origine (ma non dal file variazioni poiché il record letto dal file variazioni non è ancora stato utilizzato).
16 codice record variazioni = codice record origine: il codice da elaborare è presente sia nel file origine che nel file variazioni.
Il record del file variazioni rappresenta una modifica del record del file origine;
viene quindi richiamata la procedura VARIAZIONE che copia nel file NUOVO il record letto dal file VARIAZIONI, cioè il record con le modifiche;
per l'elaborazione successiva si deve leggere un record da ognuno dei due file e quindi vengono posti a "vero" i segnali relativi.
18 codice record variazioni codice record origine:
il record nel file variazioni non è contenuto nel file origine;
deve essere inserito prima degli altri record del file origine;
viene quindi richiamata la procedura IMMISSIONE che provvede a ricopiare il record dal file VARIAZIONI al file NUOVO.
Per l'elaborazione successiva si deve leggere un altro record dal file variazioni e quindi viene impostata a "vero" la variabile LETTURAVARIAZIONI.
Da 23 a 40 procedura di lettura dei file. Durante l'elaborazione si potrebbe verificare il caso in cui si raggiunge la fine di uno soltanto dei due file origine e variazioni;
in tal caso si devono aggiungere nel nuovo file tutti i record rimanenti del file non ancora terminato.
Per poter continuare ad usare anche in questo caso lo stesso procedimento descritto in precedenza, si può fare in modo che la situazione di fine file corrisponda a quella in cui il codice di un ipotetico ultimo record contenga il codice più alto possibile, in modo che, delle tre possibilità derivanti dal confronto dei codici, si verifichi sempre quella necessaria a completare l'elaborazione.
Da 24 a 31 viene eseguita la lettura di un record dal file origine solo se il segnale LETTURAORIGINE è impostato a vero;
in tal caso se il file non è finito viene letto un record, altrimenti se è stata raggiunta la fine del file il campo CODICEORIGINE viene impostato al valore maggiore possibile, per esempio usando un codice di 5 cifre il valore massimo è 99999;
il segnale che ha permesso la lettura viene impostato a "falso" in modo da impedire successive letture, se non espressamente richieste riportando a "vero" il segnale.
Da 32 a 39 lo stesso procedimento viene seguito anche per il file VARIAZIONI.
CANCELLAZIONE
Non esiste una vera e propria istruzione per eseguire la cancellazione di un record da un file sequenziale; anche per poter cancellare dei record è necessario ricopiare il file, omettendo i record da eliminare.I FILE AD ORGANIZZAZIONE INDEXED
LA GESTIONE
L'organizzazione indexed è ammessa solo per i file registrati su disco (e non per i file su nastro). Nel tracciato record del file deve essere individuato un campo principale, detto chiave, che identifica il record. La chiave deve essere univoca all'interno del file, cioè il contenuto del campo chiave di un record deve essere diverso da quello di ogni altro record dello stesso file; in alcuni casi sono consentiti anche file con chiavi duplicate (cioè file in cui due o più record hanno per chiave lo stesso valore). Questo tipo di organizzazione consente sia l'accesso sequenziale che l'accesso diretto; l'accesso sequenziale non consente di accedere ai record in ordine di immissione, come nei file sequenziali, ma secondo l'ordinamento dato dal valore della chiave; l'accesso diretto consente di richiedere di elaborare direttamente un determinato record indicandone la chiave. Gli schemi per la gestione con accesso sequenziale sono analoghi a quelli visti per i file ad organizzazione sequenziale tenendo presente che: - per la creazione del file, i valori delle chiavi dei record immessi devono essere ordinati, per esempio per valori crescenti; - in fase di lettura, i record vengono letti in ordine di chiave. Per l'inserimento di un record nel file in modo diretto (random) la chiave può avere un qualsiasi valore purché non già esistente nel file (ovviamente se non sono permesse chiavi duplicate). Lo schema per l'inserimento di un record con accesso random è il seguente: inizio apertura del file in output richiesta di continuazione lettura RISPOSTA mentre RISPOSTA = "S" richiesta dati lettura dati preparazione dati del record {in particolare la chiave} inserimento record richiesta di continuazione lettura RISPOSTA fine mentre chiusura del file fine L'algoritmo sembra molto simile a quello visto per i file sequenziali ma la differenza fondamentale è che in questo caso i record non vengono inseriti uno dopo l'altro, ma in modo casuale in base al valore della chiave del record. Rileggendo il file in modo sequenziale si ottengono i record in ordine di chiave anche se in modo random sono stati inseriti prima record con chiave maggiore, poi altri con chiave minore in modo disordinato. Indicando la chiave, può essere richiesta la lettura di un record qualsiasi. E' possibile che il record cercato non sia presente nel file; in questo caso viene attivato un segnale che indica che l'operazione di ricerca ha avuto esito negativo. Lo schema per la lettura di un record con accesso random è il seguente inizio apertura del file in input richiesta di continuazione lettura RISPOSTA mentre RISPOSTA = "S" richiesta valore campo chiave preparazione chiave del record lettura del record dal file se il record viene trovato elaborazione del record altrimenti operazioni in caso di record non esistente fine se richiesta di continuazione lettura RISPOSTA fine mentre chiusura del file fine Per i file ad organizzazione indexed è possibile cancellare o variare un record sia accedendo al file in modo sequenziale che in modo random. Quando si accede al file in modo sequenziale, l'operazione di cancellazione o variazione agisce sull'ultimo record letto; quando invece si accede in modo random l'operazione viene effettuata sul record individuato dal contenuto del campo chiave.LA CANCELLAZIONE DI RECORD DA UN FILE
A volte, invece di eseguire effettivamente una cancellazione, eliminando il record dal file, è preferibile usare un tipo di gestione diverso. Si può prevedere nel tracciato del record un campo destinato a contenere un segnale di annullamento. Una cancellazione corrisponde in questo caso ad una variazione del record per apporre il segnale di annullamento. Diventa possibile quindi anche esaminare i record annullati ed eventualmente ripristinarli. Questa gestione è a carico del programmatore: i programmi devono stabilire come comportarsi in presenza di record annullati e consentire le operazioni di annullamento e disannullamento. ESEMPIO 44. Si vuole scrivere un programma che permetta di gestire interattivamente le informazioni anagrafiche registrate in un file ad organizzazione indexed, cioè di effettuare ricerche di dati, inserimenti e variazioni; il file ha come chiave un codice associato ad ogni persona e tracciato:+----------------------------------------------------------------+ ¦ CODICE ¦ NOME ¦ DATA NASCITA ¦ LUOGO NASCITA ¦ VIA ¦ CITTA' ¦ +----------------------------------------------------------------+CODICE: codice identificativo della persona: è il campo chiave; NOME: cognome e nome; DATANASCITA, LUOGONASCITA: data e luogo di nascita; VIA, CITTA': indirizzo di residenza; Descrizione delle variabili:
+----------------------------------------------------------------+ ¦ NOME ¦ TIPO ¦ I/O ¦ SIGNIFICATO ¦ +-----------+-------------+------------------+-------------------¦ ¦ NOMENUOVO ¦ alfanumerico¦ input ¦variazione del nome¦ ¦DATANASCITA¦ alfanumerico¦ input ¦variazione della ¦ ¦ NUOVA ¦ ¦ ¦data di nascita ¦ ¦ LUOGO- ¦ alfanumerico¦ input ¦variazione del ¦ ¦ NASCITA ¦ ¦ ¦luogo di nascita ¦ ¦ NUOVO ¦ ¦ ¦ ¦ ¦ VIANUOVA ¦ alfanumerico¦ input ¦variazione della ¦ ¦ ¦ ¦ ¦via di residenza ¦ ¦ CITTANUOVA¦ alfanumerico¦ input ¦variazione della ¦ ¦ ¦ ¦ ¦città di residenza ¦ ¦ IMMISSIONE¦ booleano ¦ interno ¦segnale che può ¦ ¦ ¦ ¦ ¦assumere i valori: ¦ ¦ ¦ ¦ ¦"falso" = ¦ ¦ ¦ ¦ ¦variazione, "vero" ¦ ¦ ¦ ¦ ¦= inserimento ¦ ¦ DATI ¦ alfanumerico¦ input ¦segnale che può ¦ ¦ ¦ ¦ ¦assumere i valori: ¦ ¦ ¦ ¦ ¦S = si intende ¦ ¦ ¦ ¦ ¦procedere nello ¦ ¦ ¦ ¦ ¦aggiornamento del ¦ ¦ ¦ ¦ ¦codice richiesto, N¦ ¦ ¦ ¦ ¦= non si intende ¦ ¦ ¦ ¦ ¦procedere, si vuole¦ ¦ ¦ ¦ ¦richiedere un nuovo¦ ¦ ¦ ¦ ¦codice ¦ ¦ FINE ¦ booleano ¦ interno ¦segnale che può ¦ ¦ ¦ ¦ ¦assumere i valori: ¦ ¦ ¦ ¦ ¦"falso" = la ¦ ¦ ¦ ¦ ¦elaborazione non è ¦ ¦ ¦ ¦ ¦finita, "vero" = ¦ ¦ ¦ ¦ ¦fine della ¦ ¦ ¦ ¦ ¦elaborazione ¦ +----------------------------------------------------------------+Flow chart Esempio 44 (prima parte)
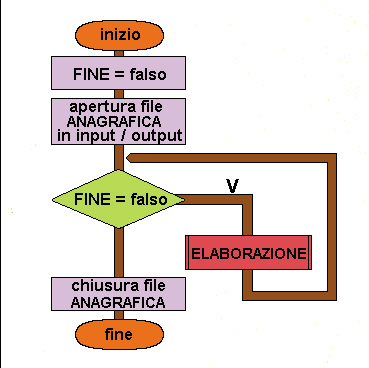
Flow chart Esempio 44 (seconda parte)
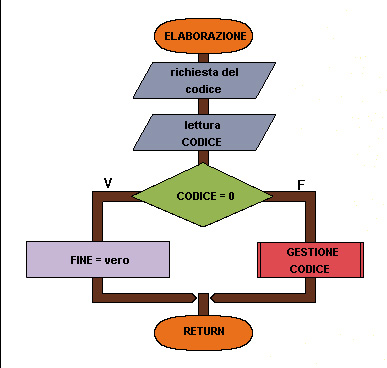
Flow chart Esempio 44 (terza parte)
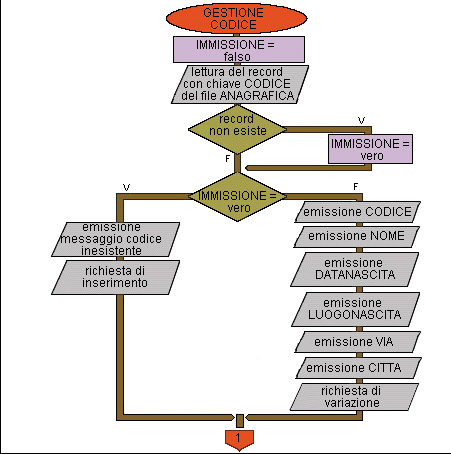
Flow chart Esempio 44 (quarta parte)
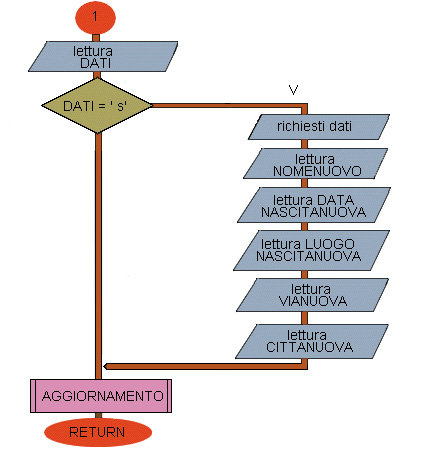
Flow chart Esempio 44 (quinta parte)
Pseudocodifica (vedi Figure)
1 inizio
2 FINE = falso
3 apertura file ANAGRAFICA in input/output
4 mentre FINE = falso esegui
5 ELABORAZIONE
6 fine mentre
7 chiusura file ANAGRAFICA
8 fine
9 inizio ELABORAZIONE
10 emissione richiesta del codice
11 lettura CODICE
12 se CODICE = 0 allora
13 FINE = vero
14 altrimenti
15 GESTIONECODICE
16 fine se
17 fine ELABORAZIONE
18 inizio GESTIONECODICE
19 IMMISSIONE = falso
20 lettura del record con la chiave indicata dal file ANAGRAFICA
21 se il record non esiste allora
22 IMMISSIONE = vero
23 fine se
24 se IMMISSIONE = vero allora
25 emissione messaggio dati inesistenti
26 emissione richiesta di inserimento
27 altrimenti
28 emissione CODICE
29 emissione NOME
30 emissione DATANASCITA
31 emissione LUOGONASCITA
32 emissione VIA
33 emissione CITTA
34 emissione richiesta di variazione
35 fine se
36 lettura DATI
37 se DATI = "S" allora
38 emissione richiesta dati
39 lettura NOMENUOVO
40 lettura DATANASCITANUOVA
41 lettura LUOGONASCITANUOVO
42 lettura VIANUOVA
43 lettura CITTANUOVA
44 fine se
45 AGGIORNAMENTO
46 fine GESTIONECODICE
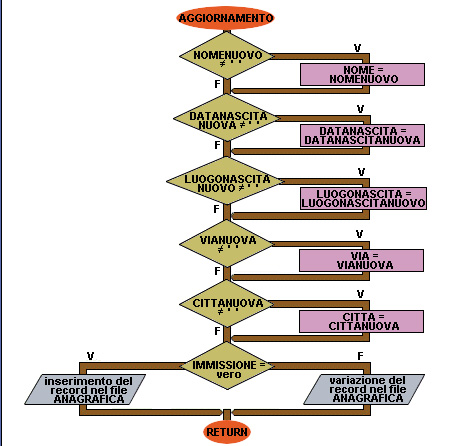
47 inizio AGGIORNAMENTO
48 se NOMENUOVO > " " allora
49 NOME = NOMENUOVO
50 fine se
51 se DATANASCITANUOVA > " " allora
52 DATANASCITA = DATANASCITA NUOVA
53 fine se
54 se LUOGONASCITANUOVO > " " allora
55 LUOGONASCITA = LUOGONASCITANUOVO
56 fine se
57 se VIANUOVA > " " allora
58 VIA = VIANUOVA
59 fine se
60 se CITTANUOVA > " " allora
61 CITTA = CITTANUOVA
62 fine se
63 se IMMISSIONE = vero
64 scrivi il record nel file ANAGRAFICA
65 altrimenti
66 varia il record nel file ANAGRAFICA
67 fine se
68 fine
AGGIORNAMENTO da 1 a 8
Programma principale 2
Il segnale FINE viene impostato a falso in modo che l'elaborazione possa cominciare;
FINE viene impostato a "vero" quando l'utente inserisce il valore 0 alla richiesta del codice da elaborare.
3 Il file ANAGRAFICA viene aperto in input/output perché i dati possano essere letti per visualizzarli, ma anche aggiornati.
Da 4 a 6 l'elaborazione si ripete finché FINE diventa uguale a "vero", per far terminare il programma l'utente deve inserire il valore 0 alla richiesta del codice anagrafico;
il programma è una ripetizione di richiesta di un codice e gestione di tale codice, che termina quando alla richiesta del codice viene introdotto il valore 0.
Da 9 a 17 procedura di elaborazione di un codice anagrafico.
10-11 Richiesta all'utente del codice desiderato.
Da 12 a 16 se il codice inserito è 0 viene impostato a vero il segnale FINE che farà terminare il programma, altrimenti inizia la procedura di gestione di un codice.
Da 18 a 46 Procedura di gestione di un codice.
19 la variabile IMMISSIONE viene impostata inizialmente a "falso", supponendo che il codice richiesto esista;
verrà impostata a "vero" se il record con il codice richiesto non viene trovato nel file.
20 Ricerca del record nel file.
Da 21 a 23 Impostazione di IMMISSIONE a "vero" se il codice non esiste.
Da 24 a 26 se il codice non esiste si avverte l'utente, chiedendo se vuole inserire i dati relativi a quel codice;
Da 28 a 34 se il codice esiste vengono visualizzati i dati relativi e si chiede all'utente se vuole apportare delle variazioni ai dati.
36 Lettura della risposta data dall'utente (può avere valore S o N) e vale sia per il caso di richiesta di inserimento che per il caso di richiesta di variazione.
Da 37 a 44 se la risposta è "S", cioè si vogliono inserire o variare i dati, viene consentito l'inserimento dei dati: nome, data di nascita ecc.
45 Viene richiamata la procedura di aggiornamento dei dati.
Da 47 a 64 procedura di aggiornamento dei dati.
Da 48 a 62 prima di sostituire i valori si verifica che ci sia effettivamente un dato nel campo letto;
procedendo in questo modo in caso di variazione l'utente deve riscrivere solo il valore dei campi che vanno realmente aggiornati, e il suo lavoro risulta quindi molto più semplice;
ogni campo del record viene cambiato soltanto se è stato effettivamente inserito il nuovo valore corrispondente.
Da 63 a 67 se il codice non esisteva il record preparato viene inserito nel file, altrimenti viene variato il record già esistente.
I FILE AD ORGANIZZAZIONE RELATIVE
L'organizzazione relative è permessa soltanto per file su disco (e non per quelli su nastro). Nei file ad organizzazione relative ogni record è individuato da un numero che esprime la posizione relativa del record all'interno del file. Questo tipo di organizzazione consente sia l'accesso sequenziale (in ordine di numero relativo di record) che l'accesso diretto, richiedendo in questo caso che venga indicato il numero del record a cui si desidera accedere in creazione o ricerca. La gestione del file è analoga a quella trattata nel caso di organizzazione indexed, avendo cura di sostituire la parola 'numero relativo di record ' alla parola 'chiave.Lo schema per l'inserimento di record in modo random nel file è: inizio apertura del file in output richiesta di continuazione lettura RISPOSTA mentre RISPOSTA = "S" richiesta dati lettura dati preparazione dati del record preparazione numero record inserimento record richiesta di continuazione lettura RISPOSTA fine mentre chiusura del file fine Lo schema per la lettura di record in modo random è: inizio apertura del file in input richiesta di continuazione lettura RISPOSTA mentre RISPOSTA = "S" richiesta numero record lettura del record dal file se il record esiste elaborazione del record altrimenti operazioni in caso di record non esistente fine se richiesta di continuazione lettura RISPOSTA fine mentre chiusura del file fine.
Ripasso di Matematica per Informatica
Matematica Programmazione Strutture Cicliche
Strutture Iterative while for do C++
Programmazione C Ciclo Pre-condizionale (while)
INFORMATICA - PROGRAMMAZIONE
Altri Sistemi Operativi Basic Dati e Le Prime Istruzioni Il Trattamento dei Dati Le Funzioni Intrinseche o Predefinite Le Istruzioni di Controllo Linguaggio e Ambiente di Sviluppo Procedure e Funzioni Programmi Dos Suono e Grafica Ricerche Complementari Vettori e Matrici Borland Delphi Caratteristiche dei Linguaggi di Programmazione I Data Base I File Ricerche Complementari I File I Linguaggi di Programmazione I Pacchetti Applicativi Sistemi Operativi Ricerche Complementari Sistemi Operativi Il Multimedia Il Sistema Operativo Dos Ricerche Complementari Il Sistema Operativo Dos Internet e Intranet Introduzione La Programmazione Interfaccia Utente L'Ambiente Microsoft Windows Le Applicazioni Ricerche Complementari Le Applicazioni Le Periferiche del Computer Le Reti di Computer Le Reti Ricerche Complementari Le Strutture di Dati Ricerche Complementari Le Strutture di Dati L'Hardware del PC Ricerche Complementari L'Hardware del Personal Computer Linguaggi Ricerche Complementari Microsoft Visual Basic Periferiche Ricerche Complementari Programmazione la Struttura Condizionale Le Matrici Dall'Algoritmo al Programma I File I Primi Elementi I Vettori Il Controllo degli Errori La Grafica L'Analisi Top Down Programmazione RAD Programmazione Le Matrici Rappresentazione Dati in Memoria Ricerche Complementari Sistemi di Numerazione Storia del Computer Struttura e Funzionamento del Computer Ricerche Complementari Struttura e Funzionamento del Computer
![]()
![]()
Enciclopedia termini lemmi con iniziale a b c d e f g h i j k l m n o p q r s t u v w x y z
Storia Antica dizionario lemmi a b c d e f g h i j k l m n o p q r s t u v w x y z
Dizionario di Storia Moderna e Contemporanea a b c d e f g h i j k l m n o p q r s t u v w y z
Lemmi Storia Antica Lemmi Storia Moderna e Contemporanea
Dizionario Egizio Dizionario di storia antica e medievale Prima Seconda Terza Parte
Storia Antica e Medievale Storia Moderna e Contemporanea
Dizionario di matematica iniziale: a b c d e f g i k l m n o p q r s t u v z
Dizionario faunistico df1 df2 df3 df4 df5 df6 df7 df8 df9
Dizionario di botanica a b c d e f g h i l m n o p q r s t u v z
![]()
